
코틀린의 컬렉션
강성우, 10 June 2020
코틀린의 컬렉션에서 사용 되는 함수들 위주로 정리 하였다. 이 함수들은 다른 언어에서도 사용 되는 함수들과 유사 하며 거기에 홤수형 프로그래밍의 장점들이 잘 녹아있다고 생각 된다.
만약 코틀린으로 개발을 하고 있다면 이러한 유틸리티성 함수들에 대한 고민을 하게 될 것이고 해결방법으로 아래의 표준화된 함수들을 찾아 사용 하거나 직접 확장함수 등 으로 만들어 사용 하는 방법이 있다. 몰론 표준 함수를 사용 하는것이 협업을 위주로 작업 할 때 가독성 면에서 좋은 효과를 보일 것 이다. 몰론 이 표준함수를 무조건 사용해야 하는 것은 아니라고 생각한다. 환경 및 필요에 따라 직접 함수를 구현 하는 방법도 있으니 상황에 맞게 고민하는것 도 좋다.
1. Overview
코틀린에서 사용 되는 컬렉션들은 2가지 타입의 인터페이스로 제공 된다. 그것은 read-only 최초 값 초기화 한 뒤 해당 값에 대해 읽기만 가능한 Immutable 한 인터페이스와, 내부 값을 다시 수정할 수 있는 mutable, 2가지 타입이 존재 한다.
아래 다이어그램 이미지는 코틀린의 컬렉션 인터페이스들의 상속관계를 보여준다.
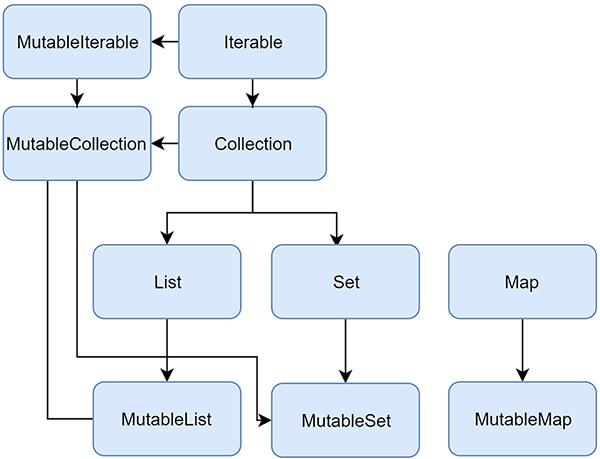
아래 정리된 내용은 코틀린의 컬렉션을 사용 하는데 유용한 인터페이스를 예제 코드 위주로 정리 하였다.
2. Iterators
Iterable<T> 인터페이스를 구현한 컬렉션에 한해 iterator 인스턴스를 가져다 내부 원소들을 이터레이셔닝 할 수 있다. 사용법은 Java와 동일 하다.
// 일반적인 방법
val list = listOf(1, 2, 3, 4, 5)
val iterator = list.iterator()
while (iterator.hasNext()) {
println("${iterator.next()}")
}
// for iteration
for (e in list) {
println("$e")
}
// for each function
list.forEach {
println("$e")
}
// for each with index function
list.forEachIndexed { index, value ->
println("$index[$value]")
}
2.1 List iterators
List에 한정적으로 사용 할 수 있는 ListIterator 가 있다. 이 iterator 는 0 번째 index 에서 list의 size 로 하나씩 혹은 그 반대인 list.size 에서 0 번째 인덱스로의 두가지 방향의 iterator 를 제공 한다.
val list = listOf(1, 2, 3, 4, 5)
val listIterator = list.listIterator()
while (listIterator.hasNext()) {
// 0 번째 부터 list.size 까지
}
while (listIterator.hasPrevious()) {
println("index: ${listIterator.previousIndex()}, value: ${listIterator.previous()}")
}
3. Range and Progressions
컬렉션의 값 들을 range 를 이용 하여 특정 인덱스 에서 특정 인덱스까지의 값을 이터레이션 할 수 있다. rangeTo 외에도 downTo, until, step 등의 오퍼레이터 함수가 있다.
if (i in 1..4) { // (1 <= 1 && 1 <= 4) 와 같다.
// ...
}
for (i in 1..4) {
// 1, 2, 3, 4
}
for (i in 4 downTo 1) {
// 4, 3, 2, 1
}
for (i in 1..8 step 2) {
// 1, 3, 5, 7
}
for (i in 8 downTo 1 step 2) {
// 8, 6, 4, 2
}
for (i in 1 until 5) {
// 1, 2, 3, 4 (마지막 원소 5 가 제외됨)
}
4. Sequence
코틀린에서 사용 되는 일반적인 컬렉션 함수들은 내부에서 parameter 로 전달받은 컬렉션 들을 연산한 뒤 중간에 새로운 컬렉션을 만들어 result value 들을 저장 하고 반환 하는 방식이다. 그렇기 때문에 효율적이지 않다. 아래 함수를 보면 filter() 함수에서 filterTo() 함수로 ArrayList<T> 를 생성해서 전달함을 알 수 있다.
public inline fun <T> Iterable<T>.filter(predicate: (T) -> Boolean): List<T> {
return filterTo(ArrayList<T>(), predicate)
}
public inline fun <T, C : MutableCollection<in T>> Iterable<T>.filterTo(destination: C, predicate: (T) -> Boolean): C {
for (element in this) if (predicate(element)) destination.add(element)
return destination
}
해당 함수들은 inline 으로 작성 되어 있기는 하지만 컬렉션의 원소의 수가 많고 처리될 그리고 처리되어진 원소가 많을 수록 새로 생성되는 List, 그리고 새로 생성된 List 에 담길 원소의 숫자는 늘어나며 그만큼 퍼포먼스에 큰 영향을 끼칠 수도 있다. 그에 대해 Sequence 를 이용 하여 chain function call 을 함수 콜 하나 하나 씩 처리 하여 중간에 새로운 인스턴스를 생성하지 않고 처리 해 주는 방식이다.
public fun <T> Sequence<T>.filter(predicate: (T) -> Boolean): Sequence<T> {
return FilteringSequence(this, true, predicate)
}
internal class FilteringSequence<T>(
private val sequence: Sequence<T>,
private val sendWhen: Boolean = true,
private val predicate: (T) -> Boolean
) : Sequence<T> {
override fun iterator(): Iterator<T> = object : Iterator<T> {
val iterator = sequence.iterator()
var nextState: Int = -1 // -1 for unknown, 0 for done, 1 for continue
var nextItem: T? = null
private fun calcNext() {
while (iterator.hasNext()) {
val item = iterator.next()
if (predicate(item) == sendWhen) {
nextItem = item
nextState = 1
return
}
}
nextState = 0
}
override fun next(): T {
if (nextState == -1)
calcNext()
if (nextState == 0)
throw NoSuchElementException()
val result = nextItem
nextItem = null
nextState = -1
@Suppress("UNCHECKED_CAST")
return result as T
}
override fun hasNext(): Boolean {
if (nextState == -1)
calcNext()
return nextState == 1
}
}
}
위 는 Sequence 에서 사용 되는 filter() 함수의 구현내용인데 FilteringSequence<T> 를 구현하여 내부에서 이터레이션 처리 함을 알 수 있다.
Sequence 는 원소의 크기가 많은 컬렉션에 대해서만 사용 하는게 좋다. 기존 컬렉션의 함수들은 대부분 inline 으로 작성 되어 있어 체이닝 함수들의 중간 값을 저장하게 될 컬렉션을 제외 하면 퍼포먼스 영향이 크지 않기 때문이다. Sequence 를 사용 하는 큰 이유는 filter, find, map 등의 일반적으로 체이닝 방식을 사용해서 처리 할 때 중간값이 저장될 컬렉션의 생성 여부이다.
5. Common operations
5.1 Mapping
이터레이셔닝 하면서 기존 <T> 리스트 타입에서 <R> 새로운 리스트 타입으로 일괄 변환한 컬렉션을 만든다.
val list = listOf(1, 2, 3, 4, 5)
println(list.map { e -> "${e * 10}" }) // -> [10, 20, 30, 40, 50] from Int to String
println(list.mapIndexed {index, e -> e * 10})
val set = setOf(1, 2, 3, 4, 5)
set.mapNotNull { }
set.mapIndexedNotNull { index, e -> }
val map = mapOf("1" to 1, "2" to 2, "3" to 3)
map.mapKeys { }
map.mapValues { }
5.2 Zipping
두개의 같은 타입 원소를 가진 컬렉션을 하나의 컬렉션으로 합친다.
val colors = listOf("red", "brown", "grey")
val animals = listOf("fox", "bear", "wolf")
println(colors zip animals)
val twoAnimals = listOf("fox", "bear")
println(colors.zip(twoAnimals))
val colors = listOf("red", "brown", "grey")
val animals = listOf("fox", "bear", "wolf")
println(colors.zip(animals) { color, animal -> "The ${animal.capitalize()} is $color"})
val numberPairs = listOf("one" to 1, "two" to 2, "three" to 3, "four" to 4)
println(numberPairs.unzip())
5.3 Association
특정 List 컬렉션을 map 으로 만든다. 함수에 전달될 값 이 value 가 되며 기존 List의 value 는 Key 가 된다.
val list = listOf("b", "zxx", "cdef", "gg", "zxcc5")
println(list.associateWith { it.length }) // {b=1, zxx=3, cdef=4, gg=2, zxcc5=5}
5.4 Flattening
여러개의 같은 값 타입을 갖지만, 서로 다른 컬렉션(List, Set, Map) 을 하나로 합쳐준다.
val numberSets = listOf(setOf(1, 2, 3), setOf(4, 5, 6), setOf(1, 2))
println(numberSets.flatten()) // -> [1, 2, 3, 4, 5, 6, 1, 2] 중복값이 존재 한다.
flatmap() 이란 함수는 기존 List 에서 map 을 하고 난 뒤 하나의 List 로 반환하게 한다.
val list = listOf(1, 2, 3)
println(list.flatMap { listOf(it + 10) }) // [11, 12, 13]
6. Filtering
컬렉션을 이터레이션이 하면서 특정 조건에 따라 필터링 처리된 원소들의 목록을 얻는다.
val list = listOf(1, 2, 3, 4, 5)
println(list.filter { it % 2 == 0 }) // [2, 4]
list.filterIndexed { index, e -> }
List<Any> 형태로 여러가지 타입이 같이 저장된 컬렉션에서 특정 타입의 원소들만 필터링 할 수도 있다.
val list = listOf(1, "two", 3, "four", 5, 6.2f, null)
println(list.filterIsInstance<String>()) // [two, four]
7. Grouping
List<T> 에서 function 에서 반환되는 값T 를 기준으로 map 처럼 key-value 형태로 정렬 해 준다.
val list = listOf("kim", "park", "kang", "lee", "paik", "jo")
println(list.groupBy { it.first() }) // {k=[kim, kang], p=[park, paik], l=[lee], j=[jo]}
8. Retrieving Collection Parts
list에서 보유한 원소의 일부들을 가져오는 방법들 이다. 원소의 일부란 0개 일수도 있고 1개 혹은 list 의 size의 크기를 가질 수 있다.
8.1 Slice
slice() 를 이용하여 특정 인덱스에서 특정 인덱스 까지의 원소들의 배열을 가져 온다.
val list = listOf("kim", "park", "kang", "lee", "paik", "jo")
println(list.slice(1..3)) // [park, kang, lee]
println(list.slice(0..4 step 2)) // [kim, kang, paik]
8.2 Take and Drop
take() 를 이용 하여 특정 인덱스의 원소만 얻거나 drop() 을 이용하여 해당 원소만 제거한 나머지를 얻는다. 이 함수들에서 …Last 가 붙은 경우 마지막 인덱스, 즉 list.size() 를 기준으로 해당 원소에 대한 처리를 한 결괄를 얻는다.
val list = listOf("kim", "park", "kang", "lee", "paik", "jo")
println(list.take(2)) // [kim, park]
println(list.takeLast(2)) // [paik, jo]
println(list.drop(1)) // [park, kang, lee, paik, jo]
println(list.dropLast(1)) // [kim, park, kang, lee, paik]
println(list.takeWhile { !it.startsWith("l") }) // [kim, park, kang]
println(list.takeLastWhile { it !== ("lee") }) // [paik, jo]
println(list.dropWhile { it.length == 2 }) // [kim, park, kang, lee, paik, jo]
println(list.dropLastWhile { it.contains("o") }) // [kim, park, kang, lee, paik]
8.3 Chunked
chunked() 는 패러미터로 주는 int 값에 따라 list 의 원소들을 해당 값 크기 만큼 나누어 새로운 List<List<T>> 로 반환한다.
val list = (0..15).toList()
println(list.chunked(3)) // [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11], [12, 13, 14], [15]]
println(list.chunked(5)) // [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9], [10, 11, 12, 13, 14], [15]]
8.4 Wndowed
windowed() 는 chunked() 와 비슷하게 패러미터 int 값 만큼 새로운 list 로 나누어주지만 조금 다르다. 기본적으로 step 이라 불리는 값(default value 는 1) 만큼 증가 하면서 해당 step 이 증가 될 때마다 step 의 인덱스로부터 패러미터로 전달받은 size 만큼 나눈다.
val list = (0..5).toList()
println(list.windowed(3)) // [[0, 1, 2], [1, 2, 3], [2, 3, 4], [3, 4, 5]]
9. Retrieving Single Elements
컬렉션에서 하나의 원소를 가져오는 방법들 이다.
9.1 Retrieving by position
list 에서 특정 position 에 존재 하는 원소를 가져오기 위한 방법들이다.
val list = listOf("kim", "park", "kang", "lee", "paik", "jo")
println(list.elementAt(1))
println(list.first())
println(list.last())
println(list.elementAtOrNull(10))
println(list.elementAtOrElse(10) { index -> "$index value has not founded" })
9.2 Retrieving by condition
주어진 함수를 통해 특정 조건에 해당 하는 원소를 찾아 반환한다.
val list = listOf("kim", "park", "kang", "lee", "paik", "jo")
println(list.first { it.length == 2 })
println(list.last { it.startsWith("k") })
println(list.firstOrNull { it.length > 10 })
println(list.find { it.length == 2 })
9.3 Checking existence
list 에서 특정한 값을 가진 원소가 존재 하는지 여부를 얻는다.
val list = listOf("kim", "park", "kang", "lee", "paik", "jo")
println(list.contains("lee")) // true
println("lee" in list) // true
println(list.containsAll(listOf("park", "lee"))) // true
10. Ordering
코틀린의 Collection 의 원소들을 정렬 하는 방법은 여러가지가 있다. 예를 들어 Java 에서도 사용 되었었던 Comparable 인터페이스의 구현을 통해서도 동일하고 사용 할 수 있다. Comparable 인터페이스의 compareTo() 메소드의 구현 및 반환 값은 Java 와 동일 하다.
10.1 Natural order and Custom order
sorted() 함수와 soretedDescending() 을 통해 자연 정렬을 하여 원소들을 정렬 한다. 그리고 sortedBy() 와 sortedWith() 를 통해서 정렬 조건을 적용 할 수도 있다.
val list = listOf("kim", "park", "kang", "lee", "paik", "jo")
println(list.sorted()) // [jo, kang, kim, lee, paik, park]
println(list.sortedBy { it.length }) // [jo, kim, lee, park, kang, paik]
println(list.sortedWith(compareBy { it.length } )) // [jo, kim, lee, park, kang, paik]
10.2 Reverse Order
reversed(), asReversed() 함수를 이용해 원소들을 역순으로 재 정렬 시켜준다.
val list = (1 .. 10).toList()
println(list.reversed())
println(list.asReversed()) // -> [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
10.3 Random order
shuffled() 함수를 이용해 원소를 섞어준다.
val list = (1 .. 10).toList()
println(list.shuffled()) // [7, 1, 3, 8, 6, 9, 2, 4, 10, 5]
println(list.shuffled()) // [9, 10, 8, 7, 4, 1, 5, 3, 2, 6]
11. Collection Aggregate operations
Kotlin 컬렉션에는 일반적으로 사용되는 집계 작업(컬렉션 내용에 따라 단일 값을 반환하는 작업)을위한 함수가 포함되어 있다. 일반적으로 잘 알려진 함수들이며 다른 언어들과 동일하게 작동한다.
예를 들면, max(), min(), average(), sum(), count(), maxBy(), minBy(), maxWith(), minWith(), sumBy(), sumByDouble() 함수들이 있다.
11.1 Fold and reduce
reduce() 와 fold() 함수는 각 리스트의 각 항목을 이터레이션 하면서 함수를 통해서 값을 반환하고 그것을 다음 원소와 함께 새로운 값을 도출 하기 위해 함수를 적용 한다. 설명 하면 어렵지만 아래의 reduce() 예제를 보면 쉽게 이해할 수 있다.
val list = listOf(12, 3, 97, 32, 8)
println(list.reduce { sum, element -> sum + element })
위 코드를 실행시 152 라는 최후 값을 얻는다. 이터레이션 상태를 보면 아래와 같다.
sum = 12, element = 3, return value = 15sum = 15, element = 97, return value = 112sum = 112, element = 32, return value = 144sum = 144, element = 8, return value = 152
reduce() 에서 패러미터로 전달 되는 고차함수내 의 패러미터는 리스트의 원소를 이터레이션 할 때마다 그 결과값이 다음 함수의 패리미터로 전달됨을 알 수 있다. 최초 실행시 0번째와 1번째 인덱스의 값이 고차함수에 전달됨도 확인 할 수 있다.
fold() 는 reduce() 함수와 하는 역활은 동일하지만 처음에 주어지는 초기값을 설정 해야 한다. reduce() 함수의 경우 0번째 인덱스를 초기화 값으로 잡고 이터레이셔닝 하였지만 fold() 는 다르게 진행 된다. 위와 같은 코드지만 아래 예제를 보면 알 수 있다.
val list = listOf(12, 3, 97, 32, 8)
println(list.fold(0) { sum, element -> sum + element })
위 실행코드는 아까 reduce() 와 동일한 결과를 얻게되지만 내부의 흐름은 조금 다르다. fold() 함수를 실행할때 패러미터로 0 이라는 값이 주어졌음을 확인 하자.
sum = 0, element = 12, return value = 12sum = 12, element = 3, return value = 15sum = 15, element = 97, return value = 112sum = 112, element = 32, return value = 144sum = 144, element = 8, return value = 152
만약 초기값을 다르게 주면 어떻게 될까? 그 흐름과 결과는 아래와 같다.
val list = listOf(12, 3, 97, 32, 8)
println(list.fold(46) { sum, element -> sum + element })
sum = 45, element = 12, return value = 58sum = 58, element = 3, return value = 61sum = 61, element = 97, return value = 158sum = 158, element = 32, return value = 144sum = 144, element = 8, return value = 152
위 reduce() 와 fold() 의 경우 첫번째 인덱스부터 이터레이션이 시작된다. 만약 리스트의 size 즉, 마지막 원소부터 0번째 인덱스 까지 역순으로 이터레이션하면서 처리 하고 싶다면 reduceRight() 와 foldRight() 를 사용 하면 된다.
이터레이셔닝 하면서 index 를 얻고 싶다면 reduceIndexed(), reduceRightIndexed() 와 foldIndexed(), foldRightIndexed() 를 사용 하면 된다.